一些常见的模型量化方法
# 前言
# 什么是量化?
将高精度运算转化到低精度上运算,例如float32转化为int8数据上运算。
# 为什么要量化?
那就要说说量化的好处了,一般量化有以下好处:
- 减小模型尺寸和存储空间,如int8量化可减少75%的模型大小;
- 加快推理速度,访问一次32位浮点型可以访问四次int8型,运算更快;
- 减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗;
- 支持微处理器,有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化;
但是其也有一些缺点:
- 增加了操作复杂度,有时会有一些特殊处理,甚至会有tradeoff,比如你发明了一个牛13的算子,可惜现有的量化工具不支持,自己实现又头大,只能忍痛割爱;
- 会损失一定的精度,所以有时会有微调,但也会有损失;不过值得一提的是,每次我用openvino量化,精度不降低反而还会升高一丢丢。这是因为模型参数是非常冗余的,量化可以看成一种正则化技术,会提升模型的泛化能力,可能在测试集上会表现好一点。不过都是事后诸葛的理论分析了,具体还是要看测试指标的。
# 怎么量化?
虽然量化方法很多,但并无本质区别。记住一点就可以了:将高精度数据映射到低精度表达,在低精度上运算,然后再反量化回去,因为最终的输出我们还是要高精度的数据的。
——摘自《pytorch量化备忘录》
需要注意的是,量化的方法根据其量化目的的不同而有很大的区别:
- 针对计算的量化:主要的需求是减小模型的计算量,要求特征图直接以量化的形式进行计算
- 针对压缩的量化:主要的需求是减小模型或特征占用的空间,特征图不需要以量化的形式进行计算
这两种量化目的带来的最大区别在于量化映射的均匀和非均匀:
- 均匀量化:y=ax+b,量化之后的数值进行加减乘除等计算与不量化直接计算在数学上等价(比如做加法:x1+x2=y1/a1+y2/a2−b1/a1−b2/a2)
- 非均匀量化:量化之后的数值进行加减乘除计算后与不量化直接计算在数学上不一定等价
所以很显然,针对计算的量化只能进行线性映射,而针对压缩的量化还可以进行非线性映射。
而在神经网络的计算过程中,特征图上的概率分布大都是非线性的,通常接近与正态分布或指数分布,非线性映射可以处理这种非均匀分布的情况。所以如果不涉及量化计算(模型参数量化等任务),通常用非线性映射的量化(特征压缩等任务)。
信号幅度的概率分布一般是不均匀的,小信号出现的概率远大于大信号。例如,一般情况下负载电流值都小于额定电流值,而且是正弦波形信号。因此用一种合理的方法,即在小信号范围内提供较多的量化级(△u为一个小值),而在大信号范围内提供少数的量化级(△u为一个大的值),这种技术叫做做非均匀量化。当每级发生的概率相同时,非均匀量化系统将更正确地恢复原始信号,使编码信号携带最大信息。在极端情况下,某一级永不出现,那么这一级提供的信息是零。在总量化级保持一定的情况下,非均匀量化系统在较大信号范围内的适应能力优于均匀量化系统。非均匀量化对于测量系统而言保持了相对误差的一致性,即小信号小误差,大信号大误差。
# 均匀标量量化 (Uniform Scalar Quantization)
重要参考:量化计算白皮书
将一个浮点数x∈(xmin,xmax)映射(量化)为一个整数xQ∈[0,Nlevels−1]。实际情况中常见int8量化,其Nlevels=256。
线性映射量化的参数有缩放比例Δ和零点z两个;方法有对称和非对称两种。
# 非对称量化(Uniform Affine Quantizer)
非对称量化是指将浮点数缩放后加上零点z:
xintxQ=round(Δx)+z=clamp(0,Nlevels−1,xint)
其中:
clamp(a,b,x)=a=x=bx≤aa≤x≤bx≥b
反量化计算为:
xfloat=(xQ−z)Δ
# 带着量化直接算卷积
线性映射的好处就在这,可以直接量化值计算与浮点计算等价,而量化值计算速度快,因此可以加速神经网络模型的训练和推理。
y(k,l,n)y(k,l,n)=ΔwΔxconv(wQ(k,l,m;n)−zw,xQ(k,l,m)−zx)=conv(wQ(k,l,m;n),xQ(k,l,m))−zwk=0∑K−1l=0∑K−1m=0∑N−1xQ(k,l,m)−zxk=0∑K−1l=0∑K−1m=0∑N−1wQ(k,l,m;n)+zxzw
# 对称量化(Uniform Affine Quantizer)
对称量化不使用零点z,而是直接将浮点数进行缩放,相当于非对称量化中零点z=0的特殊情况:
xintxQxQ=round(Δx)=clamp(−Nlevels/2,Nlevels/2−1,xint)=clamp(0,Nlevels−1,xint)if signedif un-signed
反量化计算就很简单:
xout=xQΔ
# 非均匀标量量化 (Nonuniform Scalar Quantization)
很显然,神经网络中的大部分特征的数值不会遵循均匀分布,而是在不同数值区域有不同的密度。
实际上,大部分的神经网络特征图数值都遵循正态分布或是指数分布。
因此一个直观的想法是,量化公式可以为不同的数值区域分配不同密度的量化门限,让分布密集的数值区域精度高一点,分布稀疏的数值区域精度低一点。于是就产生了非线性映射。
那很显然,非线性映射不能保证像线性映射那样能直接加减乘除,所以一般只用于特征压缩,不用于计算加速。
# Logistic映射
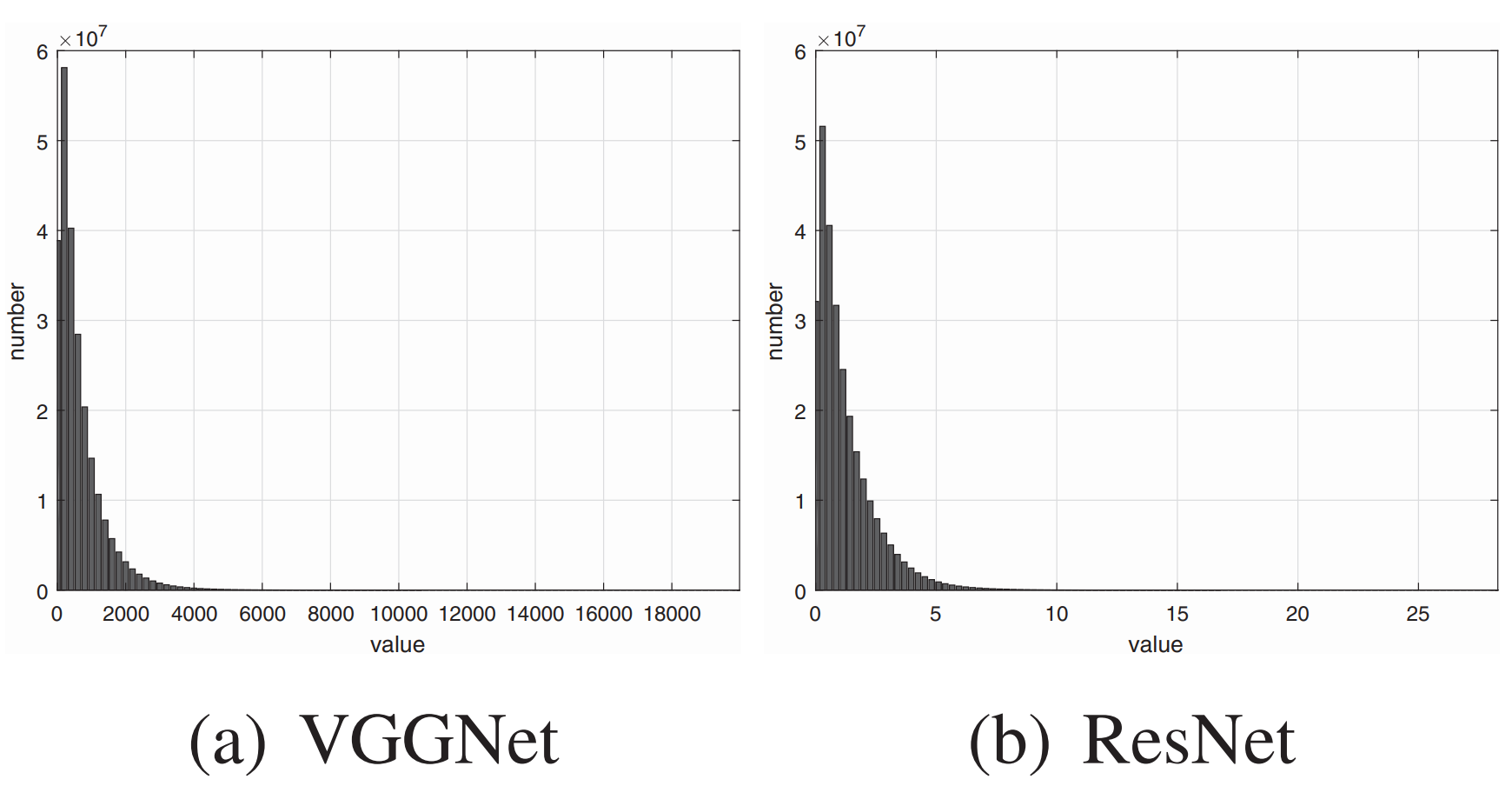
xQ=round(max(log(x−min(x)+1))log(x−min(x)+1)(Nlevels−1))
其切分密度随数值大小变化如下:

可以看到,其密度并非均匀,而是随数值增大而不断增大,因此适合于从0开始,概率密度不断减小的分布。比如:
参考论文:
- Z. Chen, K. Fan, S. Wang, L.-Y. Duan, W. Lin, and A. Kot, “Lossy Intermediate Deep Learning Feature Compression and Evaluation,” in Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, Oct. 2019, pp. 2414–2422. doi: 10.1145/3343031.3350849.
- Z. Chen, L.-Y. Duan, S. Wang, W. Lin, and A. C. Kot, “Data Representation in Hybrid Coding Framework for Feature Maps Compression,” in 2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 3094–3098. doi: 10.1109/ICIP40778.2020.9190843.
# Lloyd-Max量化
Lloyd-Max量化又称为pdf-最佳量化器,其核心思想就是在密的地方细量化,在疏的地方粗量化,从而使得每个量化区间的输入数量大致相等:
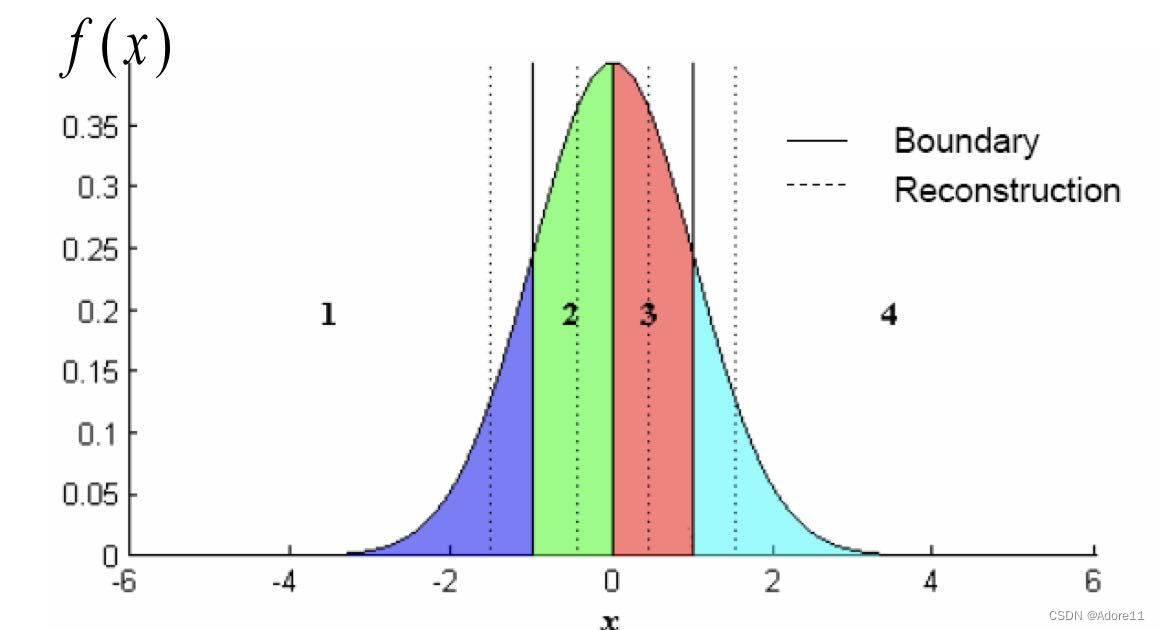
PS: 在压缩系统中,还有一个非常重要的问题需要我们考虑——我们要将量化后的结果输入熵编码,最终得到编码后的码流。而熵编码(以典型的Huffman编码为例),最希望输入的其实是一个概率分布很不均的信号,Huffman编码可以对概率大的符号采用短码,对概率小的符号采用长码,从而降低平均码长,提高压缩效率。而Lloyd-Max这种量化使得各符号的概率大致相等,所以不利于熵编码。
# 矢量量化 (Vector Quantization)
用码书中与输入矢量最匹配的码字的索引代替输入矢量进行传输与存储,而解码时仅需要简单地查表操作
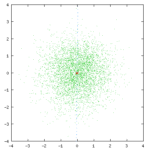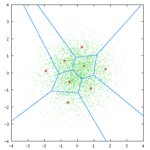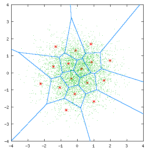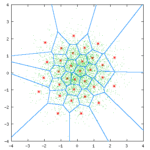
各类矢量量化讲解文中都会拿出这样一张图解释矢量量化过程:
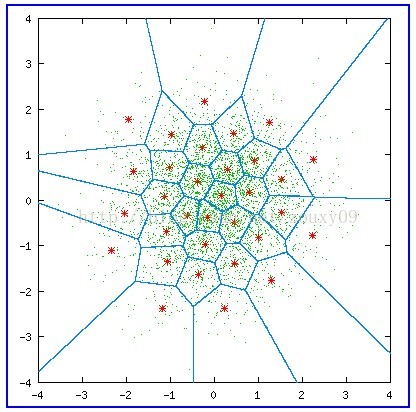
其中,绿色点对应输入坐标,红星点为量化输出,共有32个红心点,即量化后的数据宽度为5bit,蓝色的线划分了每个量化输出对应的区域;
量化过程:对于每个绿色点,其所在的区域的红心点的编号(0-31)为量化结果。
反量化过程:根据绿色点的量化结果(红心点编号)查出红心点坐标,即反量化结果。
| 名词 | 解释 | 对应内容 |
|---|---|---|
| code vectors | 码矢 | 红星点坐标 |
| encoding regions | 编码区域 | 蓝色的划分区域 |
| codebook | 码书 | 红星点编号和坐标的对应关系表 |
上面这张图称为沃罗诺伊图(Voronoi diagrams),也称作狄利克雷镶嵌(Dirichlet tessellation),是由俄国数学家Georgy Fedoseevich Voronoi建立的空间分割算法。灵感来源于笛卡尔用凸域分割空间的思想。在几何,晶体学建筑学,地理学,气象学,信息系统等许多领域有广泛的应用。
# K-means矢量量化
K-means矢量量化的原理就是用K-means将矢量数据聚为指定数量的类,然后每一个类用一个量化值代替即可。
比如我想将一个由32位浮点型的三维矢量(r,g,b)组成的图片I:Ik=(rk,gk,bk)量化为32位整型数值q∈[0,232−1]组成的图片,那么K-means矢量量化可以表示为:
- q=Kmeans(r,g,b)∈[0,232−1]:用K-means算法将图片中的所有像素(r,g,b)聚为232个类别,每个类别对应一个32位整型数值q
- (rq,gq,bq)=C(q):记下每个类别的聚类中心
于是需要保存数据就是一张记录了每个聚类中心的位置及其对应的整形数值的查找表(rq,gq,bq)=C(q)
整个图片的量化过程Q(⋅)就是用聚类中心对应的整形数值代替32位浮点型的三维矢量:
Iq=Q(I):Ikq=Kmeans(rk,gk,bk)
而反量化过程就是根据整形数值查找对应的聚类中心:
Id=D(Iq):Ikd=C(Ikq)
# Linde-Buzo-Gray (LBG) 矢量量化
其实矢量量化和k-mean 差不多,区别在于矢量量化是从一个码矢开始分裂的,而k-mean一开始就给你N个聚类中心
LBG算法码矢分裂过程: