机器学习中的Attention机制
前置知识:RNN和LSTM
# 没有注意力机制的Encoder-Decoder模式——以LSTM为例
回顾一下LSTM的单元结构:
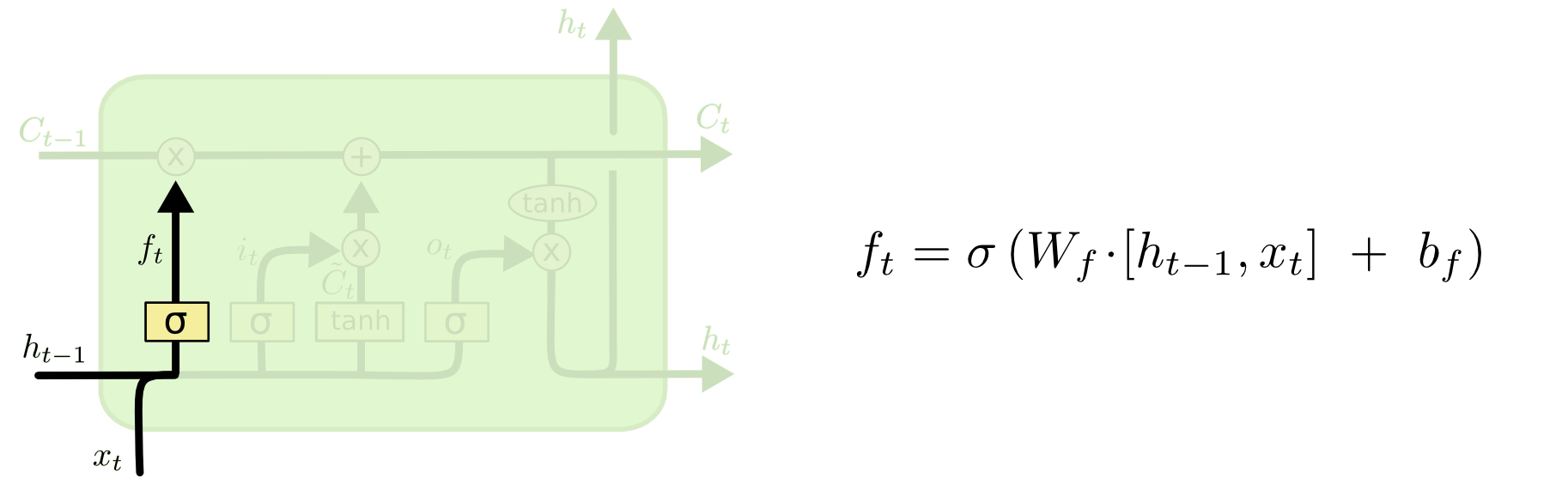
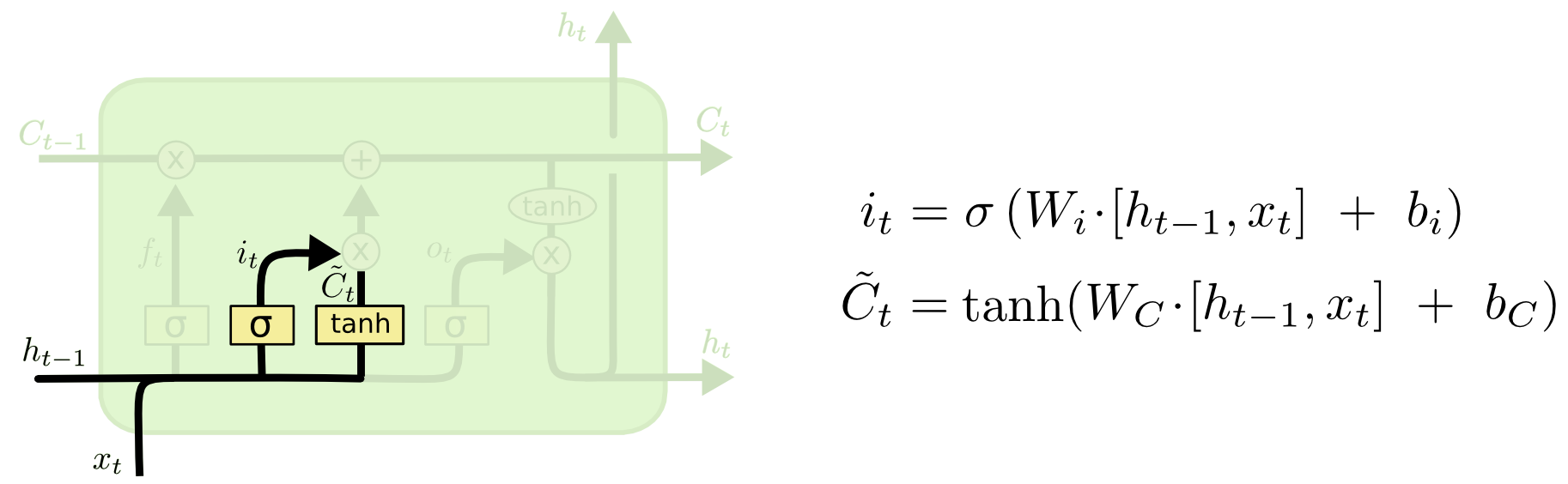
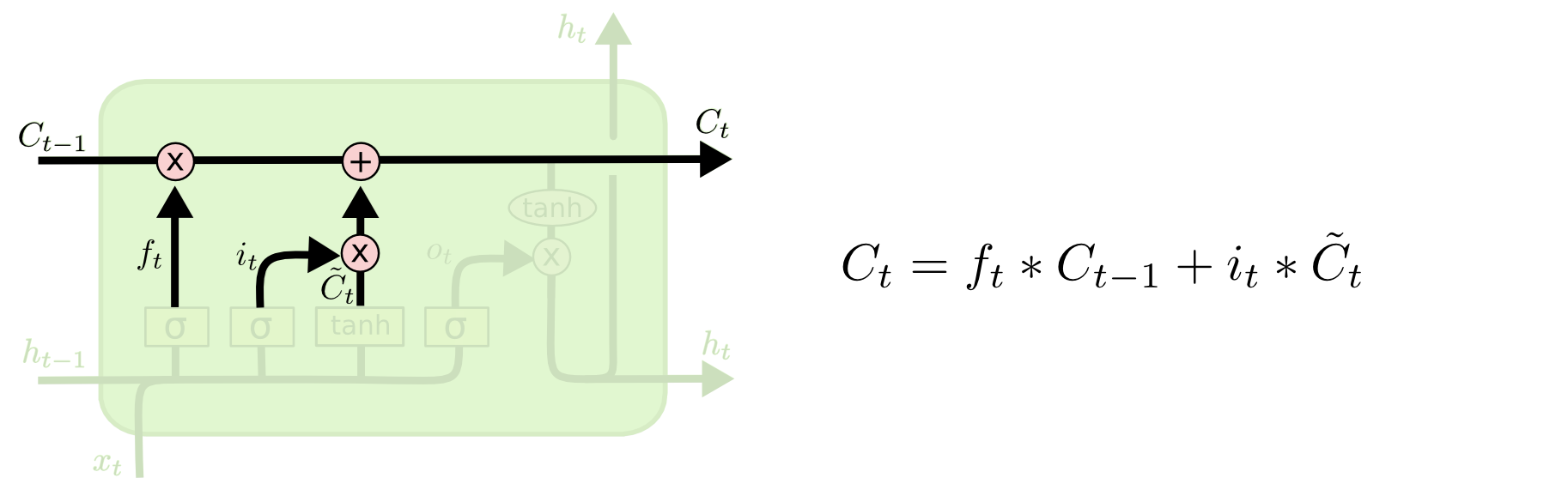
总的来说,LSTM输入一串xt,输出一串ht,在计算过程中每一轮都会有cell stateCt和ht一起进入下一轮计算
而Encoder-Decoder模式,一言以蔽之,就是使用一个RNN在一个序列上运行的最终状态输入到另一个RNN中生成另一个序列:
- Encoder使用一个RNN网络读入一个长为m的串{xt∣1≤t≤m},并输出最终的状态C作为为“语义编码”
- 如果RNN是LSTM,那么C=(hm,Cm)
- Decode使用一个RNN网络以语义编码C为初始状态生成长n的序列{yt∣1≤t≤n}
- 生成序列中的下一个值时将上一个生成的值作为输入
Encoder相当于将句子读一遍,告诉Decoder这个句子的意思,Decoder根据句子的意思再自己组织语言输出新句子。
Encoder-Decoder模式特别适合于“输入序列A,输出序列B”这种模式的应用,比如Seq2Seq就是输入一个句子(原文),输出另一个句子(译文);类似的应用还有语音识别(输入一段语音,输出一个句子)、语音合成(输入一个句子,输出一段语音)等。
# Encoder-Decoder结构

输入序列(Source):
⟨x1,x2,…xm⟩
输入序列逐个输入到Encoder中,Encoder的最终的cell state作为语义编码:
C=F(x1,x2,…xm)
Decoder以语义编码作为初始状态,第i轮输入yi−1输出yi,进而逐个生成输出序列:
yi=G(C,y1,y2,…yi−1)
输出序列(Target):
⟨y1,y2,…yn⟩
可以看出,Encoder-Decoder结构并非只能在RNN中使用:
- 只要是输入序列输出固定长度编码的结构都能作为Encoder
- 只要是输入固定长度编码输出序列的结构都能作为Decoder
# 典型用例:Seq2Seq
Seq2Seq是一种基于LSTM实现的机器翻译神经网络,其结构是Encoder-Decoder模式的典型代表。

- Encoder输入序列可以以字母为单位或以单词为单位(词向量)
- Decoder输入序列的第一个字符是起始符
\t








# 为何需要Attention机制?
回忆一下无Attention机制的Encoder-Decoder生成输出序列的过程:
C=F(x1,x2,…xm)
yi=G(C,y1,y2,…yi−1)
展开之后具体看看:
y1y2y3yi=G(C)=G(C,y1)=G(C,y1,y2)…=G(C,y1,y2,…yi−1)
从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的语义编码C都是一样的,没有任何区别。这意味着不论是生成哪个单词,源句子中的每个单词对生成目标句子的单词的影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
# Attention机制
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.))(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
这意味着,对于Decoder中输出每个字符,处理使用语义编码C之外,还要使用一个与注意力有关的项:
y1y2y3yi=G(C,S1)=G(C,S2,y1)=G(C,S3,y1,y2)…=G(C,Si,y1,y2,…yi−1)
从而包含输出单词对每个输入单词的“注意力”。具体地,相比于Encoder-Decoder模式中的直接抛弃中间数据的方法,注意力机制将Encoder的RNN中间输出用了起来:
Si=αi,1s1+αi,2s2+…αi,msm
αi,j=H(Hi−1,sj)
其中,αi,j就是生成输出语句中第i个单词时对源语句中的第j个单词分配的注意力,其由一个函数H计算而来,这个函数在不同的论文中有不同的实现,其输入为:
- sj:输入句子第j个单词在Encoder的隐层输出
- 在LSTM中,sj=(hj,Cj)Encoder
- Hi−1:输出句子生成第i−1个单词时Decoder的隐层输出
- 在LSTM中,Hi=(hi,Ci)Decoder
# 加入Attention机制后的Encoder-Decoder
(ICLR 2015) Neural Machine Translation by Jointly Learning to Align and Translate

输入序列(Source):
⟨x1,x2,…xm⟩
输入序列逐个输入到Encoder中,Encoder保存所有的中间状态:
si=F(x1,x2,…xi)i∈[1,m]
Encoder最终状态作为语义编码:
C=sm
Decoder以语义编码作为初始状态,在第i轮中输入yi−1和注意力项输出yi,进而逐个生成输出序列:
αi,j=H(Hi−1,sj)
Si=αi,1s1+αi,2s2+…αi,msm
yi=G(C,Si,y1,y2,…yi−1)
输出序列(Target):
⟨y1,y2,…yn⟩
# 案例
第一篇Attention论文中使用的H(Hi−1,sj)函数是将sj向量和Hi−1向量拼成一个长向量与一个矩阵W相乘,经过tanh之后再与一个向量v相乘成为标量:
H(Hi−1,sj)=vT⋅tanh(W⋅(sj,Hi−1)T)
在训练时,除了训练神经网络的参数,还要训练W和v。
# 效果


# 流行的K、Q、V表示法和上面这些公式的关系
网上流行的K、Q、V表示法比上面Attention RNN的这些公式更接近Attention机制的本质。上面这些公式可以说只是K、Q、V表示法的一种特殊情况。
网上流行的K、Q、V表示法可以表示为:
Attention(Query,Source)=i=1∑∣Source∣Similarity(Query,Keyi)Valuei
照着前文中的公式对应一下是这样:
Si=Attention(αi,s)=j=1∑mH(Hi−1,sj)sj
所以你看上面Attention RNN的这些公式中H(Hi−1,sj)其实就对应的是Similarity(Query,Keyi),K和Q的计算就包含在H(Hi−1,sj)里;而V就直接是sj。真正的注意力机制可以这么描述:
把输入看成是一堆(Key,Value)对,给定输出中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
——引自《深度学习中的注意力机制》
与上面的Attention RNN公式中的H(Hi−1,sj)对应,可以明白K就应该是从sj中计算出来的量,Q就应该是从Hi−1中计算出来的量,V就应该是sj,∑i=1∣Source∣Similarity(Query,Keyi)实际上就是在计算sj和Hi−1的相似性得出注意力值。
# 自注意力机制
有了“输入看成是一堆(Key,Value)对”的概念并且以“K、Q、V表示法”理解了注意力机制之后,就可以开始学习自注意力机制了(Self Attention)了。
一言以蔽之,自注意力机制实际上就是把用RNN才能算的注意力计算过程换成了简单的矩阵计算
即将:
Similarity(Query,Key)Value=i=1∑∣Source∣Similarity(Query,Keyi)Valuei=j=1∑mH(Hi−1,sj)sj=vT⋅tanh(W⋅(sj,Hi−1)T)
换成:
Similarity(Query,Key)Value=softmax(dk(s⋅WQ)(s⋅WK)T)(s⋅WV)
其中s∈Rn×dmodel、WQ∈Rdmodel×dk、WK∈Rdmodel×dk、WV∈Rdmodel×dv、n表示输入序列长度、dmodel表示输入向量的特征维度、dk表示Keyi的特征的维度、dv表示Valuei的特征的维度
自注意力是Transformer中使用的注意力机制,随着Transformer的大火一起为人所知。本节就参考Transformer原论文《Attention Is All You Need》介绍自注意力机制。
上面介绍Attention RNN和自注意力网络最大的区别在于K、Q、V的计算方式。在Attention RNN中,K和V都是输入si∈R1×dmodel(词向量);Q是RNN的中间输出Hi,每一个Hi的计算都需要上一个Hi−1作为输入,所以Attention RNN和普通RNN一样只能顺序计算。而Self Attention的K、Q、V是直接由输入的词向量si乘上3个矩阵WQ、WK、WV得来的,即:
Qi=siWQKi=siWKVi=siWV
于是可以用矩阵运算一次算出一个句子里所有词的Ki、Qi、Vi:
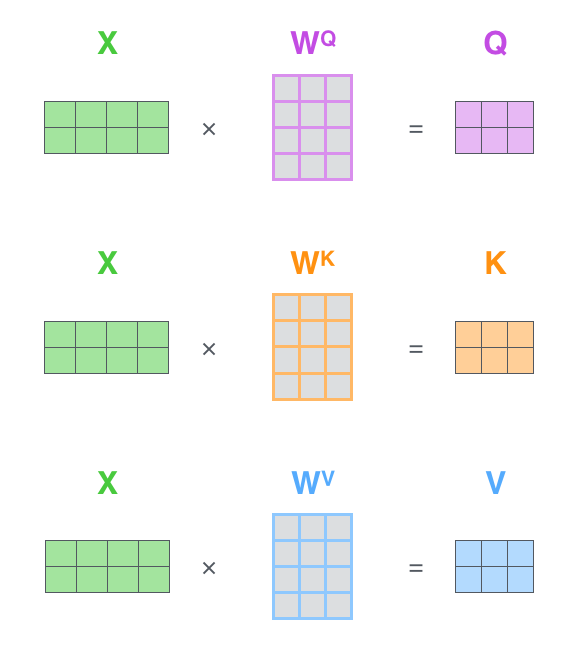
(图中的X表示所有的词向量si组成的矩阵)
最后,直接用矩阵计算出输出Attention值:
Attention(Q,K,V)=softmax(dkQKT)V
其中,dk是Ki、Qi、Vi的维度,除以dk是为了保证训练时梯度的稳定。
矩阵图示为:

结合上一节的介绍可以看到,这个softmax(dkQKT)算的就是Similarity,其结果就是一个长宽都等于输入词数量的矩阵,其中的每个值就是第i个词和第j个词的Similarity:Similarityi,j=QiKjT;输出的Z=Attention(Q,K,V)中的每一行就是每个词准备的注意力向量。
至此,Self Attention的注意力计算已经完成了,可以看到没有涉及任何解码器那边的东西,全部是在输入句子上操作,这也是它被叫做“self” attention的原因:只提取了输入句子内部的词之间的联系构成注意力参数。
并且我们还发现,这个Self Attention的注意力计算不涉及什么时序的步骤,可以并行计算。这是自自注意力的一个主要优势,也是现在大家喜欢用它的原因之一。
# 自注意力与顺序
但是问题又来了,没有时序步骤,怎么知道词的顺序信息?
答案是把位置信息搞成位置编码放进输入向量si里:
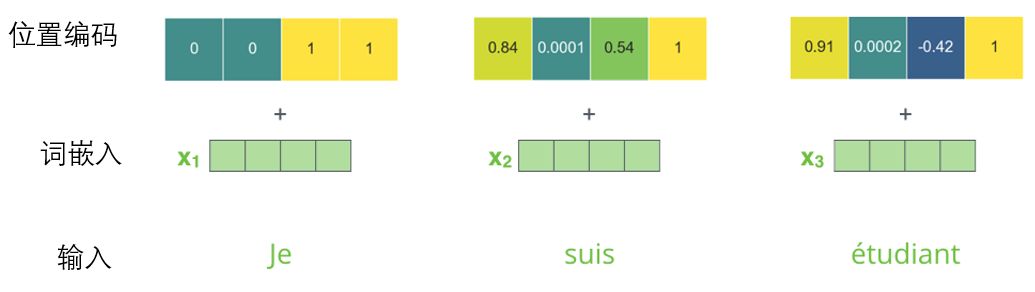
比如Transformer里的词向量为512维,位置编码长下图这样,图中每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间,颜色越深表示值越大:
![]()
可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数(使用正弦)生成,而右半部分由另一个函数(使用余弦)生成。然后将它们拼在一起而得到每一个位置编码向量。
Transformer原论文里描述了位置编码的公式(第3.5节)。你可以在
get_timing_signal_1d()中看到生成位置编码的代码。这不是唯一可能的位置编码方法。然而,它的优点是能够扩展到未知的序列长度(例如,当我们训练出的模型需要翻译远比训练集里的句子更长的句子时)。
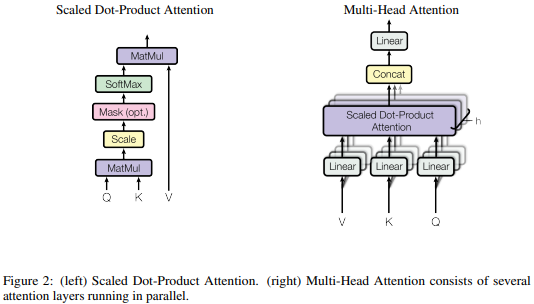
# 多头注意力
多头注意力就比较简单了,就是直接把多个独立的注意力模块拼接在一起再乘上一个矩阵就完事了:
MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)
![]()
![]()
Transformer里也用到了多头注意力,具体用了8个头。看Transformer原论文《Attention Is All You Need》里的图:
# 图像识别领域的注意力机制
F. Wang et al., ‘Residual Attention Network for Image Classification’, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, Jul. 2017, pp. 6450–6458, doi: 10.1109/CVPR.2017.683.

H. Zhao, J. Jia, and V. Koltun, ‘Exploring Self-Attention for Image Recognition’, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, Jun. 2020, pp. 10073–10082, doi: 10.1109/CVPR42600.2020.01009.
截至2020,图像识别领域的注意力机制还在火热研究中。
# 可学习的Embedding
如果位置编码可学习得到,就不用去自己找合适的位置编码函数了。缺点是如果序列长度不固定的话靠后面的位置编码值可能就更新不了几次。所以训练用的的句子最好是比投入使用时的句子长一点。
# BERT中的可学习位置编码
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
2
3
这个word_embeddings是预定义的词向量查询表;position_embeddings是位置编码,根本上就是一个矩阵,通过位置编号123查询出向量;token_type_embeddings对应的是论文里的Segments Embeddings,和位置编码同理,区别只是每一个句子对应一个Segments Embedding。
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
2
# ViT中的可学习的Projection(将Patch映射为向量)
self.projection = nn.Conv2d(num_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
实际上就是一个H × W × C都和Patch大小一样的卷积核,卷积核的输出尺寸是1 × 1 × EmbeddingSize,所以可以把Patch映射成向量。
# ViT中可学习的位置编码
self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.hidden_size))
实际上就是一个矩阵。由于ViT输入是图片,所以可以固定序列长度num_patches,从而可以对位置编码进行训练。
但如果输入图片尺寸变了,num_patches就会变,位置编码就需要重新训练。